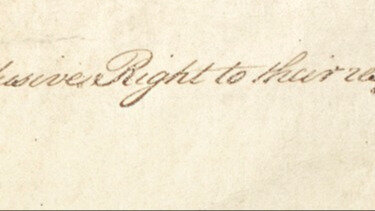

Demand tech companies release all copyright holders data used in training of Generative AI
The issue
This protest is directed against
ALL AI COMPANIES or TECH COMPANIES
in relation to
COPYRIGHTED INFORMATION
which they have
COPIED FROM COPYRIGHT HOLDERS WITHOUT THEIR OWNER’S PERMISSION.
Demanding they
***RELEASE ALL DATA ABOUT ANY COPYRIGHTED INFORMATION WHICH THEY HAVE COPIED IN SECRET WITHOUT THE OWNERS PERMISSION***
doing this under claim of Fair Use, then used the secretly copied copyrighted information to
TRAIN GENERATIVE AI PROGRAMS
which
COMPETE AGAINST THE LEGITIMATE COPYRIGHT HOLDERS IN THE MARKETPLACE
Which therefore makes the Fair Use claim invalid. You can’t copy material secretly under a claim of fair use, reassemble or as they say, ‘transform’ them together without revealing who you’ve copied from, then use the resulting content to compete against the very copyright holders which you’ve taken the information from.
That’s not Fair Use. That’s not Transformative.
That’s COPYRIGHT INFRINGEMENT.
If they don’t comply, then the justice system should:
ENFORCE COPYRIGHT LAW!
**********************************************************************
The rationale and references behind this demand follows below. If you disagree with any of this and would rather sign the demand without the very long rationale & references, I have created a second petition with the demand only here:
Rationale & References:
The rest of this document will show the proof of why this demand is being asked for: how Generative AI is illegal because it is based on illegal copying, and describe how this unchecked ingestion of a vast number of copyrighted materials from sources worldwide has given it power to operate outside the law, an illegally gained power thieved from all human creation, which harms every creator and the whole of society in a variety of ways, referencing numerous campaigns, cases, complaints and criticisms. This is why the petition is a demand for all tech companies to release information on all copyrighted data they’ve copied.
The information relating to what copyrighted material has been copied in secret by tech companies can be released voluntarily. Or it could be released by Court Order. Such as in actions like California’s Generative AI Training Data Transparency Act, in force from January ‘26.
Now American legal discussions about Fair Use soon bring up the ‘4 factor test,’ (Copyright Act, Section 107) of which generative AI fails every point:
1. Purpose & Character: Their work is commercial. Generative AI can and often does substitute for the original use of the work.
2. Nature of the Work: They often train on creative work such as art and music which is supposed to be given more copyright protection than factual work.
3. Amount and Substantiality: Fair Use is supposed to only allow a small portion of work to be taken. Instead, their training took 100% of work to be trained.
4. Effect on the Market: Substantial. They train work on copyrighted materials then repurpose the copyrighted material to compete against the exact creators it was trained on.
Reference: U.S. Copyright Office Fair Use Index, https://www.copyright.gov/fair-use/
In the above page, the context around the word ‘transformative’ is shown, which AI promoters prattle off without reading the full sentence definition from the copyright office: “Transformative uses are those that add something new, with a further purpose or different character, and do not substitute for the original use of the work.”
The key point being that last part, “and do not substitute for the original use of the work.” Many times generative AI can substitute for the original use, for instance a book might be prompted to do the exact thing as a book it was trained on, the same with a photograph or any other media which AI has copied. Next time an AI promoter prattles the word ‘transformative,’ be sure to remind them that the use cannot “substitute for the original use of the work.”
Also AI promoters often mention inventions ranging from the camera to the motor vehicle and point out those had their detractors at the time they were introduced. Painters criticised the camera, horse drawn buggy operators criticised the car and so on. It is true that most new inventions draw criticisms from people who the invention may replace or lose out in some way: AI has definitely drawn plenty of those criticisms. However, there is a key difference: all those previous inventions, from the calculator to the camera, the car, the computer and so on, were all produced legally. Generative AI is built on copyright infringement; the secret theft of millions of copyrighted works. That means that there is potential for AI companies to be sued by every copyright holding creator in every creative field in every country in the world. No other invention was built on illegal theft in the way that AI has been.
If you wanted to compare the invention of the car to AI, then it would be as though Henry Ford’s car company built his factory produced model-T cars using stolen goods: if every input in every car’s production from the tyres to the engine crankshafts were stolen from every garage in the world by thieves, that might be close to how generative AI is built on copyright theft.
Because mass copyright theft isn’t progress!
True progress would be putting a system in place which protects the copyright rights of individual creators so their works aren’t misused, or used without their permission.
Have you heard tech people say they expect that AI will replace writers? This is talked about all the time. But AI companies are the ones that copied writers material to begin with under a claim of Fair Use, on which their programs are based. There's no possible way that it's Fair Use to copy 100% of an author's material, with the intention not just to use the material to compete with the author in the marketplace which would be illegal enough, but also to replace that author, indeed replace every author, with the resulting product. Any other comments made expecting AI to replace any creative arts field is also the perfect evidence to show the original copying wasn’t Fair Use. Which is also proved if AI starts replacing the creators it was trained on: this is not Fair Use. It’s not Fair Use to replace the original creator!
AI promoters try to compare machine learning with human learning, and say the process is similar. They claim the way a person learns from everything they pick up in the course of their life should be treated the same as a data mining AI program which illegally copies bits of everything. It’s like comparing a student to an international spy. The student goes to school and learns from classes and books. The spy sneaks into companies offices and photographs blueprints. Both methods involve learning, but one is legal, the other isn’t. When the spy gets caught, under their logic he would claim, “I couldn’t have asked the companies for their secret blueprints because they would’ve said no! So I had to steal them! That’s Fair Use because the company I was selling them to planned to Transform them into a new design. Can I have a legal exception for my blueprint stealing please?”
Also their method might be like a student who broke into the teacher’s office, found a stack of assignments and copied bits of each one which they pasted together, then refused to say who they copied from when caught. (Student to Teacher: "I can’t tell you who I copied this assignment from, it’s my Trade Secret, but I’ve Transformed a few different students papers into this new work. If I’d asked you if I could copy the other students papers, you would’ve said no. Therefore, I had to copy them all! That’s Fair Use! Can I have an exemption from cheating?")
They’re a little like a robber stealing jewellery, then taking the jewellery apart, patching them together differently and trying to sell them before being caught. (Robber to police: “This isn’t the original Rolex, it’s been Transformed with a new wristband! How I made the Transformed Rolex is my Trade Secret! I couldn’t have asked the jewellery store for the Rolex to begin with, because they would have asked me to pay! Therefore, I had to rob the store! That’s Fair Use!”)
Or something like that. And I might be showing my late-Generation X age with this example, but it works the same with an Apple smart watch or whatever people have now... although Rolex still makes watches. Anyway the point is, a lot of theft/unauthorised copying took place, which tech companies want to cover up with a ‘data mining exception’ from copyright law that follows the ridiculous principle of ‘steal first, ask for a legal exception later.’ And some people are taking the attitude that these companies have stolen so much intellectual property that they’re now ‘too big to prosecute.’ That they’ve made so much money off copyright theft that they can’t be brought to justice? ‘Too big to prosecute?’ was part of the actual title of a U.S. Senate judiciary hearing into the AI Industry. What happened to the likes of President Teddy Roosevelt and his ‘trust busting?’
Another argument of AI promoters is pointing to scientific or research applications of AI. But just because a computer program has some useful application doesn't mean it needs to violate the entire world's copyright law. Any useful application of AI could have been built on public domain books and so on, without illegal theft of massive quantities of copyrighted material. You don't hear this argument in any other industry: that they 'need' to steal to produce their work.
As pointed out in the U.S. Senate judiciary hearing on ‘Too big to prosecute?: Examining the AI industry's mass ingestion of copyrighted works’ in July 2025 by best selling writer and ex trial-lawyer David Baldacci:
“These trillion dollar companies didn’t even buy my books. They got them off a website that has pirated works. They complained that it would be far too difficult to license the works from individual creators. So apparently it was more efficient to steal it. Trillion dollar companies with battalions of lawyers did not have the resources to do things lawfully. I was once a trial lawyer. If I had made that argument in court, I would either have been laughed out of the courtroom or held in contempt by the judge. And rightly so. If AI companies only needed words, they could have fed every dictionary in the world into their machine learning.”
Reference: 'No More Copyright Protection For Anyone': Author David Baldacci Rips Big Tech Over AI Copyright’
https://www.youtube.com/watch?v=0fPUWSv2JCI
Baldacci also noted in his written statement that “every major large language model in commercial use today was trained on pirated books.”
*Which was backed up by comments of three of the other four speakers at that hearing:
“Evidence shows that Gen AI companies have willfully, knowingly and repeatedly trained on pirated materials.” – B. Viswanathan
“The largest domestic piracy of intellectual property in our nation’s history.” – M. Pritt
“The use of pirated content to train generative AI models will harm sales for creators.” – M. Smith
The other speaker was more supportive of AI training regardless of the small matter of it being based on illegal copying, but did concede that “an AI model that routinely produces outputs that are infringing, such as regurgitations, might not be a fair use.” – E. Lee
He also argues that making stricter rules means that companies would go to other countries in search of less strict rules, but this isn’t a good argument: it would be like making less laws on drug dealing or whatever crime because other countries are less strict. Instead, this should be the reason why there needs to be a worldwide treaty to prevent ‘data mining’ of copyrighted materials in any country.
And he discussed the 40+ copyright law suits against AI companies in American courts, but this hearing in July 2025 is out of date: just under a year later, the figure has more than doubled!
Reference: ‘Examining the AI Industry’s Mass Ingestion of Copyrighted Works for AI Training,’ U.S. Senate Judiciary
As of June 2026, there are over 100 cases in the US legal system involving AI companies, and more across the world, as copyright holders keep finding out more about how tech companies secretly copied a massive amount of copyrighted material without their owner’s permission.
Reference: US and world maps with links to most cases, and other historic maps of the changes over time available at:
https://chatgptiseatingtheworld.com/category/map-of-ai-copyright-lawsuits/
Note: I am not connected in any way with the above site.
To be honest, as a fiction writer living in Australia with an arts degree, I don’t have any great knowledge of the legal systems of America or other countries where major tech companies are based. I’m author of books like ‘Mortal Wombat,’ which I spent more than 10 years writing, long before generative programs existed.
In writing this document, I feel a little like the guy in the Lego Movie giving the rousing speech to the group of superheroes, “I’m the least qualified person here.”
But what I do know is that tech companies have been taking a massive amount of copyrighted material and turning it into slop, and using that slop to compete against legitimate copyright holders without revealing who they’ve copied from. That’s not right, it’s not ethical, and I’m pretty sure it’s not legal.
And their claim of derivative copyright infringing slop being ‘transformative’ isn’t correct. Just like the actual Transformers, the Japanese cartoon, the pieces of the original robot can be seen in the new vehicle, like the Deceptacon/Autobots logos. In the same way that pieces of the original copyright holders work still appear in the new derivative work.
For instance generated images produced by the program ‘Stable Diffusion’ sometimes reproduced the original training image and a modified watermark for Getty Images. This is why the program developer Stability AI was sued by Getty Images – where it abandoned the main part of the case in a British court for the technicality of the program not being trained in the UK. But just because the program was produced in Germany shouldn’t mean that they can avoid copyright law – don’t the UK and Germany have all sorts of economic and copyright treaties? For instance, the Berne Convention and the TRIPS agreement – why couldn’t those have been applied somehow?
I don’t really want to get involved and start this protest. I’d much rather hide in my ‘hobbit hole’ and play World of Warcraft. But I also don’t want our future to drown in a sea of AI generated @#£%
Generative AI content can look fair, but feel foul, to paraphrase the hobbits description of the Mordor spy in Lord of the Rings. Sometimes it looks foul too! It often makes mistakes that no human would ever make, like generative pictures showing background crowd members without heads or limbs, or joined to someone else. Or messing up text in pictures. Generative content often feels lifeless or soulless.
When you watch real movies, listen to real music, read real books and so on, you know that they were the result of hours of labour by real people like yourself. Sometimes many humans worked on the artistic work in many fields such as editing etc. and had discussions and drafts before the final content was produced. This is missing from generative AI content, where a microchip spits out a patchwork of stolen material.
Ask yourself this question: over the course of your life, how much enjoyment have you received from movies, tv shows, music, games, books and other entertainment produced legitimately by copyright holders – I’m guessing hours and hours, right?, versus how much from derivative AI content – maybe a few short video clips or weird pictures? The problem is the derivative AI stuff is suffocating creators of the other, and the content’s worse, and it’s not legal anyway because it violates copyright.
Every moment the tech companies delay releasing information on what copyrighted data was copied only opens them up for more future law suits because of new material produced based on copyright infringing data.
Since about 2017, this Copyrighted material from numerous copyright holders has been secretly taken, then used by the tech companies to train generative programs, available from about 2023 onwards, to reassemble into ‘AI slop’ which competes against the legitimate copyright holders, threatening professionals right across the creative arts. Millions of artists, writers, musicians, actors, models, photographers, designers, animators, poets, podcasters, journalists and other professionals all over the world are losing out to tech companies’ computer servers, whose power and water usage are a drain on the environment.
*Reference: To just pick one action or protest from each field out of many:
*Artists, ‘The harm & hypocrisy of AI art’ by Matt Corrall, Corrall Design
https://www.corralldesign.com/writing/ai-harm-hypocrisy
*Writers, ‘More than 15,000 Authors Sign Authors Guild Letter Calling on AI Industry Leaders to Protect Writers’
*Musicians, ‘Is This What We Want?’ By 1000 musicians
https://www.isthiswhatwewant.com/
*Actors, ‘Hollywood’s stand against AI’
https://www.equaltimes.org/hollywood-s-stand-against-ai-a?lang=en
*Models, ‘British fashion models and the threats posed by indiscriminate use of Artificial Intelligence’
*Photographers, ‘Getty Images Is Suing the Company Behind Stable Diffusion, Saying the A.I. Generator Illegally Scraped Its Content’
*Games, ‘Our industry has been strip-mined’
https://www.theguardian.com/games/2025/dec/15/video-game-workers-protest-firings-the-game-awards
*Animation, ‘International Animation Unions Plan Protest Against AI’
https://variety.com/2025/film/global/animation-unions-anti-ai-protest-annecy-1236424470/
*Poets, ‘Page Against The Machine: On the Poetics of AI Refusal,’ Scottish Poetry Library
*Podcasts, ‘The podcast factory making 3,000 episodes a week,’
https://podnews.net/update/ai-slop
This example list is by no means complete. There are many more actions, protests and articles against generative AI and its potential copyright infringement.
*Then there is the massive impact AI is having on news media. The tech companies training method is described by publisher A.G. Sulzberger:
"A brazen theft of intellectual property that has occurred at an unprecedented scale. Tech giants strip-mine news websites without permission or compensation. They repackage these stolen goods as their own, siphoning off the audiences and revenue that otherwise would go to the news organizations that created this work. And this happens not just once during the training process, but countless times every single day."
He points out the society-wide impact too:
"A.I. companies have raided civilization’s entire corpus of original works, an act that also poses a danger to the future of books, movies, music, research and an array of other fields."
- Quoted from the speech, 'A.I., Journalism and the Uncertain Future of the Public Square', World News Media Congress, World Association of News Publishers, Marseille, June 2026
https://www.nytco.com/press/a-i-journalism-and-the-uncertain-future-of-the-public-square/
From many other campaigns and articles about AI's impact on news media, a few more examples :
*The 'News Not Slop' Campaign by the NewsGuild-CWA,
https://www.newsnotslop.org/demands
*'Artificial intelligence: journalism before algorithms,' National Union of (UK) Journalists,
https://www.nuj.org.uk/resource/artificial-intelligence.html
*'Real Journalists can lead the war against deepfakes,' Journalism Education & Research Association of Australia,
https://jeraa.org.au/role-of-journalists-vital-in-era-of-ai-generated-or-ai-edited-deepfakes/
Then there are many campaigns against the pollution, noise, power and water usage of AI data centres such as:
*‘AI and datacentres: a new climate threat’,
https://www.campaigncc.org/ai_data_centres_climate
*‘Get The Truth About Data Centers,’
*‘Stop Dirty Data Centers,’ NAACP,
https://naacp.org/campaigns/stop-dirty-data-centers
*‘Stop the AI Data Centre Frenzy,’ The Greens,
https://greens.org.au/vic/campaigns/stop-ai-data-centre-frenzy
*Or view the U.N. report, ‘Environmental Cost of Artificial Intelligence: Carbon, Water, and Land Footprints,’
Besides all this infringement and pollution, AI is not even working out smoothly for the industries where it's being adopted. There are of course complaints from people who AI is replacing, but there are also complaints from within the companies where AI is being used. If you search Youtube for 'AI backlash' you will find a variety of problems, from 'AI fatigue' to employers not getting back their return on AI investment, to retrenched employees being rehired after AI programs failed to work, or AI producing 'hallucinations' (mistakes which sound real), or employees being forced to use AI when there isn't a need for it, to customers being unhappy with AI products and service.
Reference: 'Nobody Actually Wants AI Anymore,'
https://www.youtube.com/watch?v=FQpZdCKgc6w
Other problems include the expensive nature of AI, for both the companies and its users, with the legal fees from ongoing copyright litigation, plus the costs of running large computer servers making hefty maintenance, power and water bills. There has been criticism that AI costs much more than the value of what it produces. Or an issue with different company employees encouraged to use ‘AI tokens’ until they became too expensive so they were banned from using them.
Reference: 'AI’s downfall is bitterly ironic,’
https://www.youtube.com/watch?v=7w_tjX04BDY
Then there's the problem which large AI companies have of being unable to stop their programs content being copied or ‘distilled’ by smaller AI companies, which seems to be standard practice in their industry. This ‘distillation’ sounds quite similar to the ‘diffusion’ of images used by AI program ‘Stable Diffusion’ in the Getty Images copyright case, so it’s a bit of poetic justice that they’re now finding themselves being distilled. When AI companies complained about this ‘distillation’ in February 2026, they received an unsympathetic community response with mocking comments like “They're plagarising our plagarism machine!”
Reference: 'AI Companies Who Steal Work Complain Competition Unfairly Stole Their Work, Get Laughed At,'
https://www.youtube.com/watch?v=EkpzQVgxKlg&t=174s
In addition to all the problems, the reassembled generated AI material enables the creation of dishonest deep fake imagery which causes scams, harassment and deception.
References, (I just picked one of each from a horrendous number of examples):
*‘How scammers use technology and AI’
*‘Artificial Intelligence and online harassment’
https://www.parkview.com/blog/artificial-intelligence-and-online-harassment
*‘AI Deception, Brief of the [United Nations] Secretary General's Scientific Advisory Board.’
https://unu.edu/cpr/policy-brief/ai-deception
This isn’t just wrong ethically and morally, it’s wrong legally.
It’s called COPYRIGHT INFRINGEMENT.
And companies can’t claim that’s a Trade Secret, as some do, because copyright infringement is illegal. Your Trade Secret can’t be illegal, that’s common sense.
If tech companies don’t release the data on what copyrighted information they’ve secretly copied under claim of Fair Use, and used to train generative AI programs to produce AI slop that competes against legitimate copyright holders, which makes the content ineligible for Fair Use - and also since illegal copyright infringement cannot be a Trade Secret, it won’t just mean many more law suits filed by copyright holders seeking damages. I believe that it proves the entire content of some companies could be considered illegal and may open the company up for compulsorary liquidation.
One American law professor which I sent this liquidation idea to, described it as “exceptionally unlikely to work,” due to copyright law being governed federally and state law covering dissolution of companies.
So it seems that an action can be pursued in state courts only after a ruling is made in U.S. federal court about the copyright infringement committed by these companies. There are actually a large number of current cases against AI companies working through federal or district courts. (The U.S. has 94 federal districts; small states have one district, large states have multiple districts.) The copyright cases as of June 2026 against AI companies in these federal/district courts are: California’s Northern District (55 cases), California’s Central District (7 cases), New York’s Southern District (37 cases), Illinois N.D. (4), Delaware (3), Massachusetts and Washington W.D. (2 each), Montana, Colorado, North Carolina W.D. (1 each)
Reference: https://chatgptiseatingtheworld.com/aicopyrightcasetracker/
So what state are AI companies corporated in? Most weren’t corporated in California where you might expect. It turns out many tech companies have corporated themselves in Delaware, the 2nd smallest state by area and 6th smallest by population, due to Delaware’s status as a ‘corporate haven,’ but that doesn’t mean they can avoid U.S. federal copyright law.
A Delaware district court is also where one of the early victories against AI occurred, in Thomson Reuters v. ROSS Intelligence (2025), where a judge ruled against the AI company for using summaries of judges opinions to train AI. Perhaps this hurt the legal system, now maybe judges would like to consider the way AI is hurting the rest of society?
It is worth noting that the Attorney General of Delaware can start the process to dissolve “any corporation” under 8 Delaware Code § 284, for the “abuse, misuse, or nonuse of its corporate powers.”
Reference: https://delcode.delaware.gov/title8/c001/sc10/index.html#284
I believe the violation of the entire world’s intellectual property rights and copyright law at once by AI companies is just such an abuse and misuse of corporate powers. If you agree with me, maybe you would like to contact the Attorney General of Delaware? I have already posted a letter to her, but she has not responded yet.
I wonder whether the Founding Fathers would approve of Delaware corporated companies which conduct no real business in Delaware breaking U.S. federal copyright law.
Such as whether the Copyright Clause may have been broken – if content being transformed into slop without permission is breaking this ‘exclusive right’? :
"To promote the Progress of Science and useful Arts, by securing for limited Times to Authors and Inventors the exclusive Right to their respective Writings and Discoveries." (U.S. Constitution, Article I, Section 8, Clause 8)
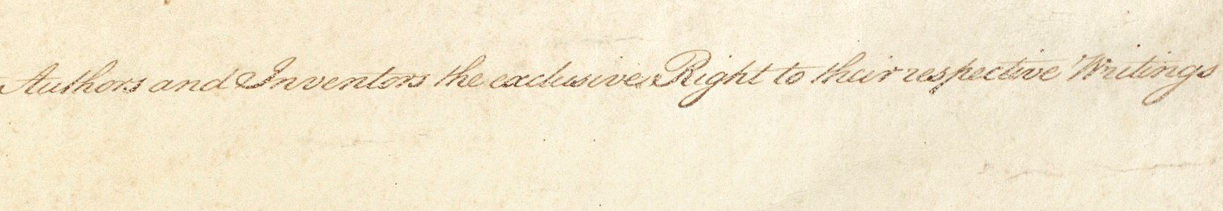
I don’t know the answer to that constitutional question and nothing here is meant as legal advice. I’m not a lawyer, and most of my understanding of copyright is based on being in a creative arts field; writing, art and images, where copyright is important. At least it was important before AI companies decided they were above copyright law and could copy anything they felt like, rewriting the rules to suit themselves. So not being a lawyer, all those complicated legal arguments are far beyond my understanding. If you are knowledgeable about American law, please consider working on the arguments to help defend the entire world’s artistic and creative products.
It may be an impossible mission to request big tech companies to reveal their ‘Trade Secret:’ all the copyrighted information which they’ve taken without permission. Of course they want us to take them at their word that they kept to Fair Use regulations, while they secretly plundered the entire world’s copyrighted information, then claim that they can’t reveal the information because it’s their ‘Trade Secret.’ Do you trust them?
I admit that this mission may have an astronomically low chance of success, but that never stopped anyone in Star Wars, right; “Never tell me the odds!”
While researching this document, I was astounded by the vast number of campaigns, protests and criticisms of AI by so many people in so many fields from so many angles, which I've only hinted at here. They really feel like the array of rebels in Star Wars banding together to fight a technologically sophisticated yet evil empire of copyright infringing AI companies which care more about their bottom line, than the environment, the arts or humanity. The spherical shape of the Death Star is not unlike the shape of the 'AI bubble.'
But we have Yoda on our side. Literally; he's one of the many copyrighted characters owned by Disney for which they are suing AI company Midjourney for copying without permission.
An empire is also what the AI industry is called in the book ‘Empire of AI’ by journalist Karen Hao, who interviewed 300+ people in the AI industry to form this theory:
“Over the years, I’ve found only one metaphor that encapsulates the nature of what these AI power players are: empires... [they] seize and extract precious resources to feed their vision of artificial intelligence: the work of artists and writers; the data of countless individuals posting about their experiences and observations online; the land, energy, and water required to house and run massive data centers and supercomputers. So too do the new empires exploit the labor of people globally to clean, tabulate, and prepare that data for spinning into lucrative AI technologies. They project tantalizing ideas of modernity and posture aggressively about the need to defeat other empires to provide cover for, and to fuel, invasions of privacy, theft, and the cataclysmic automation of large swaths of meaningful economic opportunities.”
Reference: ‘Empire of AI: Inside the reckless race for total domination.’
https://www.amazon.com.au/dp/B0F38RZP32
In one interview she explains how the promoters and supporters of the 'AI empires' act like they’re part of a religious cult!
Reference: ‘A.I. is a Religious Cult with Karen Hao,’ Interview by Adam Conover
https://www.youtube.com/watch?v=6ovuMoW2EGk
The above interview is enlightening, pointing out this absurd cult following which AI has received, playing off fear of ‘the other side’ introducing a similar AI system to the one they're promoting. I imagine a fantasy setting with an AI cultist saying something like: “The other side’s AI threatens us all, brother, but our side’s AI is not evil like theirs. So give us your Copyrighted materials, brother, and I will recite the incantation of Illegal Infringement and utter a prayer of out-of-context Transformation, then the secret spell of Unfair Use will make your Copyright disappear and the Derivative Slop will be summoned!” (Then appears one of those headless twisted monstrosities found in AI generated crowd pictures.)
The absurdity of it all would be hilarious, if it wasn’t tragic for creators, society and the environment.
These ‘AI cultists’ point to China to scare Westerners. However, rather than an ‘AI arms race’ with China, how about ‘Disarming AI’ as Pope Leo XIV has suggested? For instance we could have a U.S.-China treaty similar to the START treaty that slowed the Cold War arms race. Both sides could agree to close down a proportion of their polluting data centres, or each unincorporate a certain number of copyright-infringing AI firms? Try that suggestion next time an AI promoter wants to scare you with fearmongering.
China has their own issues with generative AI versus copyright law, with five court cases before April 2025.
Reference: Authors Alliance, ‘China’s Controversial Court Rulings on AI Output.’
China, like the United States, is signatory to the Berne Convention for the Protection of Literary and Artistic Works and the TRIPS agreement, Trade-Related Aspects of Intellectual Property Rights. On the other hand, generative AI offers no such protection, and are lobbying for more ‘licence to steal’ data mining exemptions all around the world. It doesn’t matter where the AI company is based, they’re the ones taking away copyright rights of the whole world’s creators.
The tactic of AI companies scaring people by pointing out future harms their products might cause as a way of hyping them up, is called ‘Doom trolling’ by Georgetown University Computer Science Professor Cal Newport, who points out this weird strategy is unique in the business world.
Reference: ‘Dear AI Companies: Stop the “Doom Trolling”’
https://calnewport.com/dear-ai-companies-stop-the-doom-trolling/
There has been other criticism from within their field, for instance current AI large language models said to not be an artificial intelligence at all, and instead a ‘technological hack,’ and a form of ‘pattern recognition’, as they were described in 2025 by the Professor of the Foundations of Artificial Intelligence in the Department of Computer Science at the University of Oxford.
Reference: ‘Oxford's AI Chair: LLMs are a HACK.’
https://www.youtube.com/watch?v=7-UzV9AZKeU
In addition, the huge number of computer data centres being built don't just pollute the environment, they have also reduced the supply of computers and their parts for everyday people, and driven up their price during 2025-26 up to one thousand percent more!
Reference: ‘I Was Right About AI.’ [in referring to previous video, ‘How AI Will Fail Like The Music Industry.’]
https://www.youtube.com/watch?v=aXy8mQeuObk
Whether you believe in using AI or not, the main point is this: tech companies can’t keep secret what information they’ve taken from an unknown number of copyright holders and claim that’s Fair Use. Fair Use guidelines specify a minimum amount of content taken, not all – and how is anyone supposed to know how much has been taken if the companies are keeping secret what and how much they’ve copied? How could you know if something produced with generative AI does or doesn’t breach copyright? And there are many clear cases where it has, such as direct portions of copyrighted images taken and reassembled into a new derivative copyright violating image.
For example, in 2025 when Disney teamed up with Universal Pictures, joined later by former rival Warner Brothers, to sue Midjourney, this AI company was described as “a bottomless pit of plagiarism.”
Reference: ‘Disney Enterprises Inc. v. Midjourney Inc.’, District Court, C.D. California
https://www.courtlistener.com/docket/70513159/disney-enterprises-inc-v-midjourney-inc/
In the above page, Yoda is mentioned in points 38, 82, 87, 143, 150 and 178 of their complaint, while Exhibits C & D also show many clear violations with generated images using copyrighted characters.
So people using these generative programs can’t be sure that the resulting material doesn’t violate copyright in some way, and with laws changing in different countries, they might be liable for copyright infringement sometime in the future.
Also consider that any content produced with generative AI is ineligible for copyright, and therefore public domain in most jurisdictions. So anyone can quite legally copy generative AI material and almost do what they like with it. Which means that the result of generative AI is to take copyright holders material and illegally transform it into public domain material – there’s no way it’s fair use to delete copyright holders’ copyright! Generative AI is basically a machine that copies, patches together and deletes the copyright of the original copyright holders, turning the resulting transformation into public domain in seconds, rather than waiting the 70 years after the author’s death for which entering the public domain is supposed to happen under U.S. Copyright Law.
Reference: this Wikimedia commons page covering world copyright rules:
https://commons.wikimedia.org/wiki/Commons:Copyright_rules_by_territory
In the above page, look at the collaborative effort and detail which editors have put together to cover copyright rules, with a subpage for every country in the world - rules which generative AI wants to ignore.
Indeed, American AI companies give Americans less copyright protection than Chad, Madagascar, Luxembourg, Kazakhstan or North Korea, which like 182/195 countries are signatory to the Berne Convention for the Protection of Literary and Artistic Works, giving minimums of 25 years copyright protection for photographs, and 50 years after the author’s death for most other works. And 164 countries are also signatories to the TRIPS agreement, (Trade-Related Aspects of Intellectual Property Rights) which also gives 50 year minimum copyright terms. Reference: Wikipedia.
The world needs a new treaty to protect creators from data mining by tech companies, to stop any ‘data mining exception.’ This is an ‘exception’ from the law, that allows companies to violate copyright law – oh, sorry, it’s not illegal because they've been given an ‘exception’ from the law. In any case, data mining of copyrighted materials should be illegal, and there should be a worldwide treaty banning it, an update to the Berne Convention.
This would prevent tech companies from using their pathetic argument that, ‘if you stop us stealing copyrighted materials here, people will just go to X country where they can steal copyrighted materials instead.’
I’m glad a similar argument isn’t used in every world law, where society bases its laws not on what’s right, fair or just - but on how the law is treated in whichever place happens to have the weakest laws in the world.
Even if this data mining ‘licence to steal’ is kept in place, companies should at least be forced to disclose what they have stolen – sorry, copied copyrighted information without their owner’s permission but given an exception from the law to do so, from whom. Creators have the right to know if their work has been copied.
And if every country banned data mining copyrighted theft under a new worldwide treaty, then no-one would be able to steal copyrighted materials.
When an AI generated image is produced, it is ineligible for copyright in both the European Union, the United States and many other jurisdictions, and immediately enters the public domain on its creation. Now everyone is free in theory to copy that work and make it into any work they like. The problem isn’t just that the image is being used in a way unintended by the original creator, but it also opens up its potential for being used in ways unintended either by the original creator, or the maker of the AI generated image, because it’s now not protected under copyright law. The AI content isn’t even respected by other AI companies, which often ‘distill’ their rivals content to make their own programs.
Before you think of ways you could use AI programs to make art or fiction, remember that the content produced is similar to fan-art or fan fiction, with the potential for trouble with, or even being sued by the original creator/s. But this is a much worse situation than fan art, because with generative AI the creator/s may be unknown – you don’t know for sure that some piece of the work isn’t a direct copy of some work you’ve never seen or heard. Plus you have little to no copyright protection for others to misuse the generated work in other ways, such as reselling it under a different name, which in turn might make you liable for someone in the future doing something else with the un-copyrighted generated work which you can’t predict.
With so many copyright holders infringed by generative programs turning their copyrighted material into public domain ‘AI slop’, there’s just going to be more and more litigation, as cases involving AI companies rose to over 100 in courts worldwide in 2026.
The below chart shows the copyright cases just in America. The trend was already going up, but Anthropic’s $1.5 billion settlement announcement in September 2025 showed creators can win, which might have helped cause cases against AI companies to skyrocket:
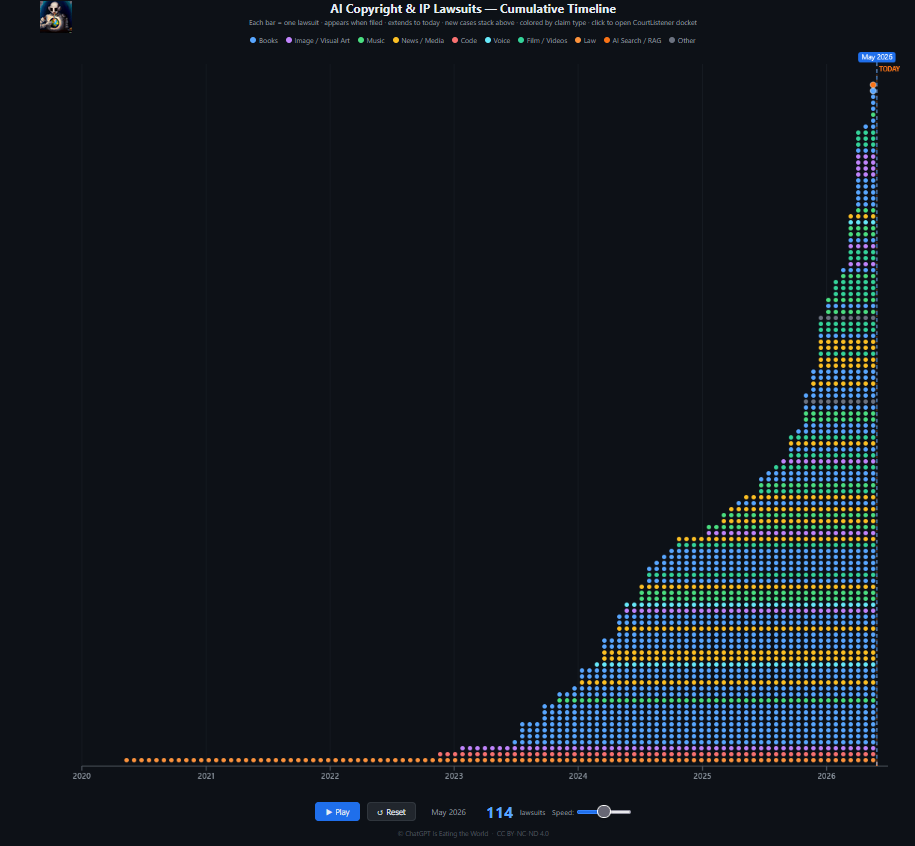
Source (on the original image, each dot is a clickable link to the actual case):
https://chatgptiseatingtheworld.com/ai-copyrightcase-timeline/
The AI bubble might soon burst, or ‘drown,’ if you will, in a sea of copyright law suits, and perhaps rightfully so, for a business model built around copyright infringement. If you've invested in AI companies, maybe sell your shares before the AI bubble bursts? Why not try 'ethical investing' instead?
Besides, AI companies may not last long beyond 2100 anyway. Because you can’t maintain computer data centres without oil, which is a critical component used in microchip production. And the Earth is going to run out of oil this century, that’s inevitable. We should be thinking about how to best use the planet’s last remaining oil reserves to prepare for a future without it, and I’m not sure generative AI making public domain copyright violations will be much help.
Better to get rid of generative AI ahead of time, before it poisons every creative arts field with derivative copyright infringing slop, enables the production of dishonest deep fake imagery that is causing so much harm to society, and pollutes the environment on its way out, all based on the mass theft of copyrighted material without permission.
Given all the problems generative AI is causing for society it shouldn't be allowed to operate where it hasn’t even obtained its training data legally. Companies should release copyright holders data, pay compensation to creators where needed, then only operate under a transparent, legal model.
When companies release this data on what copyrighted information their programs have been trained, it means creators whose works have been unlawfully copied can be justly compensated by the companies which used them without permission. Then the system can move forward with full transparency and less need for litigation. Then creators will have the right to opt out of having their creations copied if they wish, without the danger of having their own work being illegally copied and used against them to profit someone else.
Conclusion: It is an outrageous situation that programs which produce content based on mass copyright infringement are harming the world in such a variety of ways. The AI companies money, power and influence has been illegally gained based on thieving the copyrighted materials of the entire world. The imperial style power they are wielding and the money they have made is not their own: it was collectively stolen from the entire artistic product of the world. This was not Fair Use, it is not Fair Use to have their programs compete with and replace original creators. It is not Fair Use that tech companies' programs have allowed the creation of deep fake imagery that causes scams, harassment and deception. It is not Fair Use that AI companies servers are causing environmental pollution, draining power and water resources. It is not Fair Use that AI programs are replacing human jobs when their expensive programs don’t even work properly; they make hallucinations, give employees stress or fatigue and produce inferior products. It is not Fair Use that the copyrighted artistic products of the world are combined by generative programs into derivative public domain ‘AI slop’ which has no copyright protection, and can be reused by anyone for any purpose, deleting the copyright of the original creators.
Many of the world’s countries united in signing the Berne Convention for the Protection of Literary and Artistic Works. Now the world needs a new treaty to protect creators, which stop any tech company anywhere in the world from secretly thieving copyrighted data from any creative field. If 182/195 countries can sign the Berne Convention, they should be able to come together for a new treaty to force tech companies to be completely transparent with their data training. Only by forcing tech companies to release all copyrighted data, and putting in place a worldwide treaty to stop them from ever illegally thieving the creative products of the world again, can the rights of the world’s creators be protected, for so many people who just want to make an honest living in the creative arts.
Note: I am also submitting this protest to the Australian Senate’s Environment and Communications References Committee regarding ‘Artificial intelligence and data centres.’
Although I don’t know if the protest will achieve anything. There are other bigger protests out there such as the Pause AI movement at
the Statement on AI training:
https://www.aitrainingstatement.org/
or the Stealing isn’t Innovation campaign:
https://www.stealingisntinnovation.com/
And there are other current and former calls for AI companies to release copyrighted data, including:
*The ‘Authors Guild Open Letter to AI Leaders’ in November 2023
https://actionnetwork.org/petitions/authors-guild-open-letter-to-generative-ai-leaders
*The ‘Generative AI Copyright Disclosure Act’, introduced in U.S. Congress in 2024
https://en.wikipedia.org/wiki/Generative_AI_Copyright_Disclosure_Act
*The ‘Stop AI Theft’ campaign in Australia 2025
https://meaa.good.do/stopaitheft/stop-metas-AI-theft/
*The ‘Copyright Labeling and Ethical AI Reporting Act’, introduced in the U.S. Senate in February 2026, now being discussed:
https://copyrightalliance.org/press-releases/introduction-clear-act/
*California’s ‘Generative AI Training Data Transparency Act’ (2026)
https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202320240AB2013
***
While Pope Leo XIV has called for AI to be ‘disarmed’ in the 2026 encyclical letter, ‘ON SAFEGUARDING THE HUMAN PERSON IN THE TIME OF ARTIFICIAL INTELLIGENCE’,
https://www.vatican.va/content/leo-xiv/en/encyclicals/documents/20260515-magnifica-humanitas.html
*Even here at change.org are dozens of examples:
Protect authors’ livelihoods,
Ban AI in elections,
https://www.change.org/p/protect-our-democracy-ban-ai-in-elections
Stop AI image theft,
https://www.change.org/p/stop-ai-image-theft-introduce-urgent-protections
Make it illegal to create AI-generated nudes,
https://www.change.org/p/make-it-illegal-to-create-ai-generated-nudes
Stop Generated AI From Invading The Animation Industry,
https://www.change.org/p/stop-generated-ai-from-invading-the-animation-industry
Protect musicians from fraud,
https://www.change.org/p/protect-musicians-from-fraud
Protect our art and data from AI companies,
https://www.change.org/p/sign-the-manifesto-protect-our-art-and-data-from-ai-companies
And on and on. Last I checked change.org recorded more than 1000 results for “generative AI” – those are separate protests!
So my protest may be lost in the crowd, but it’s a small thing I can do which seems worth starting to help protect EVERY COPYRIGHT HOLDER IN THE WORLD FROM HAVING THEIR BEAUTIFUL COPYRIGHTED MATERIAL MISUSED AND TRANSFORMED INTO PUBLIC DOMAIN ‘AI SLOP’ WITHOUT THEIR PERMISSION.
That’s why this is a demand for
ALL TECH COMPANIES TO RELEASE ALL DATA ON ALL COPYRIGHTED INFORMATION TAKEN FROM ANY COPYRIGHT HOLDER IN SECRET WITHOUT THEIR PERMISSION, AND USED TO TRAIN GENERATIVE AI PROGRAMS.
(In other words, Obey Copyright Law! Or have governments Enforce Copyright Law.)
Either companies release this information voluntarily, or it will be released through legal action by the courts which is already happening in many cases worldwide. This copyrighted information must be protected, for it represents the livelihoods for so many people right across the creative arts.
Because You, the People, deserve not to have your artistic creations stolen.
☆HAPPY 250TH BIRTHDAY AMERICA!!!!!☆

14
The issue
This protest is directed against
ALL AI COMPANIES or TECH COMPANIES
in relation to
COPYRIGHTED INFORMATION
which they have
COPIED FROM COPYRIGHT HOLDERS WITHOUT THEIR OWNER’S PERMISSION.
Demanding they
***RELEASE ALL DATA ABOUT ANY COPYRIGHTED INFORMATION WHICH THEY HAVE COPIED IN SECRET WITHOUT THE OWNERS PERMISSION***
doing this under claim of Fair Use, then used the secretly copied copyrighted information to
TRAIN GENERATIVE AI PROGRAMS
which
COMPETE AGAINST THE LEGITIMATE COPYRIGHT HOLDERS IN THE MARKETPLACE
Which therefore makes the Fair Use claim invalid. You can’t copy material secretly under a claim of fair use, reassemble or as they say, ‘transform’ them together without revealing who you’ve copied from, then use the resulting content to compete against the very copyright holders which you’ve taken the information from.
That’s not Fair Use. That’s not Transformative.
That’s COPYRIGHT INFRINGEMENT.
If they don’t comply, then the justice system should:
ENFORCE COPYRIGHT LAW!
**********************************************************************
The rationale and references behind this demand follows below. If you disagree with any of this and would rather sign the demand without the very long rationale & references, I have created a second petition with the demand only here:
Rationale & References:
The rest of this document will show the proof of why this demand is being asked for: how Generative AI is illegal because it is based on illegal copying, and describe how this unchecked ingestion of a vast number of copyrighted materials from sources worldwide has given it power to operate outside the law, an illegally gained power thieved from all human creation, which harms every creator and the whole of society in a variety of ways, referencing numerous campaigns, cases, complaints and criticisms. This is why the petition is a demand for all tech companies to release information on all copyrighted data they’ve copied.
The information relating to what copyrighted material has been copied in secret by tech companies can be released voluntarily. Or it could be released by Court Order. Such as in actions like California’s Generative AI Training Data Transparency Act, in force from January ‘26.
Now American legal discussions about Fair Use soon bring up the ‘4 factor test,’ (Copyright Act, Section 107) of which generative AI fails every point:
1. Purpose & Character: Their work is commercial. Generative AI can and often does substitute for the original use of the work.
2. Nature of the Work: They often train on creative work such as art and music which is supposed to be given more copyright protection than factual work.
3. Amount and Substantiality: Fair Use is supposed to only allow a small portion of work to be taken. Instead, their training took 100% of work to be trained.
4. Effect on the Market: Substantial. They train work on copyrighted materials then repurpose the copyrighted material to compete against the exact creators it was trained on.
Reference: U.S. Copyright Office Fair Use Index, https://www.copyright.gov/fair-use/
In the above page, the context around the word ‘transformative’ is shown, which AI promoters prattle off without reading the full sentence definition from the copyright office: “Transformative uses are those that add something new, with a further purpose or different character, and do not substitute for the original use of the work.”
The key point being that last part, “and do not substitute for the original use of the work.” Many times generative AI can substitute for the original use, for instance a book might be prompted to do the exact thing as a book it was trained on, the same with a photograph or any other media which AI has copied. Next time an AI promoter prattles the word ‘transformative,’ be sure to remind them that the use cannot “substitute for the original use of the work.”
Also AI promoters often mention inventions ranging from the camera to the motor vehicle and point out those had their detractors at the time they were introduced. Painters criticised the camera, horse drawn buggy operators criticised the car and so on. It is true that most new inventions draw criticisms from people who the invention may replace or lose out in some way: AI has definitely drawn plenty of those criticisms. However, there is a key difference: all those previous inventions, from the calculator to the camera, the car, the computer and so on, were all produced legally. Generative AI is built on copyright infringement; the secret theft of millions of copyrighted works. That means that there is potential for AI companies to be sued by every copyright holding creator in every creative field in every country in the world. No other invention was built on illegal theft in the way that AI has been.
If you wanted to compare the invention of the car to AI, then it would be as though Henry Ford’s car company built his factory produced model-T cars using stolen goods: if every input in every car’s production from the tyres to the engine crankshafts were stolen from every garage in the world by thieves, that might be close to how generative AI is built on copyright theft.
Because mass copyright theft isn’t progress!
True progress would be putting a system in place which protects the copyright rights of individual creators so their works aren’t misused, or used without their permission.
Have you heard tech people say they expect that AI will replace writers? This is talked about all the time. But AI companies are the ones that copied writers material to begin with under a claim of Fair Use, on which their programs are based. There's no possible way that it's Fair Use to copy 100% of an author's material, with the intention not just to use the material to compete with the author in the marketplace which would be illegal enough, but also to replace that author, indeed replace every author, with the resulting product. Any other comments made expecting AI to replace any creative arts field is also the perfect evidence to show the original copying wasn’t Fair Use. Which is also proved if AI starts replacing the creators it was trained on: this is not Fair Use. It’s not Fair Use to replace the original creator!
AI promoters try to compare machine learning with human learning, and say the process is similar. They claim the way a person learns from everything they pick up in the course of their life should be treated the same as a data mining AI program which illegally copies bits of everything. It’s like comparing a student to an international spy. The student goes to school and learns from classes and books. The spy sneaks into companies offices and photographs blueprints. Both methods involve learning, but one is legal, the other isn’t. When the spy gets caught, under their logic he would claim, “I couldn’t have asked the companies for their secret blueprints because they would’ve said no! So I had to steal them! That’s Fair Use because the company I was selling them to planned to Transform them into a new design. Can I have a legal exception for my blueprint stealing please?”
Also their method might be like a student who broke into the teacher’s office, found a stack of assignments and copied bits of each one which they pasted together, then refused to say who they copied from when caught. (Student to Teacher: "I can’t tell you who I copied this assignment from, it’s my Trade Secret, but I’ve Transformed a few different students papers into this new work. If I’d asked you if I could copy the other students papers, you would’ve said no. Therefore, I had to copy them all! That’s Fair Use! Can I have an exemption from cheating?")
They’re a little like a robber stealing jewellery, then taking the jewellery apart, patching them together differently and trying to sell them before being caught. (Robber to police: “This isn’t the original Rolex, it’s been Transformed with a new wristband! How I made the Transformed Rolex is my Trade Secret! I couldn’t have asked the jewellery store for the Rolex to begin with, because they would have asked me to pay! Therefore, I had to rob the store! That’s Fair Use!”)
Or something like that. And I might be showing my late-Generation X age with this example, but it works the same with an Apple smart watch or whatever people have now... although Rolex still makes watches. Anyway the point is, a lot of theft/unauthorised copying took place, which tech companies want to cover up with a ‘data mining exception’ from copyright law that follows the ridiculous principle of ‘steal first, ask for a legal exception later.’ And some people are taking the attitude that these companies have stolen so much intellectual property that they’re now ‘too big to prosecute.’ That they’ve made so much money off copyright theft that they can’t be brought to justice? ‘Too big to prosecute?’ was part of the actual title of a U.S. Senate judiciary hearing into the AI Industry. What happened to the likes of President Teddy Roosevelt and his ‘trust busting?’
Another argument of AI promoters is pointing to scientific or research applications of AI. But just because a computer program has some useful application doesn't mean it needs to violate the entire world's copyright law. Any useful application of AI could have been built on public domain books and so on, without illegal theft of massive quantities of copyrighted material. You don't hear this argument in any other industry: that they 'need' to steal to produce their work.
As pointed out in the U.S. Senate judiciary hearing on ‘Too big to prosecute?: Examining the AI industry's mass ingestion of copyrighted works’ in July 2025 by best selling writer and ex trial-lawyer David Baldacci:
“These trillion dollar companies didn’t even buy my books. They got them off a website that has pirated works. They complained that it would be far too difficult to license the works from individual creators. So apparently it was more efficient to steal it. Trillion dollar companies with battalions of lawyers did not have the resources to do things lawfully. I was once a trial lawyer. If I had made that argument in court, I would either have been laughed out of the courtroom or held in contempt by the judge. And rightly so. If AI companies only needed words, they could have fed every dictionary in the world into their machine learning.”
Reference: 'No More Copyright Protection For Anyone': Author David Baldacci Rips Big Tech Over AI Copyright’
https://www.youtube.com/watch?v=0fPUWSv2JCI
Baldacci also noted in his written statement that “every major large language model in commercial use today was trained on pirated books.”
*Which was backed up by comments of three of the other four speakers at that hearing:
“Evidence shows that Gen AI companies have willfully, knowingly and repeatedly trained on pirated materials.” – B. Viswanathan
“The largest domestic piracy of intellectual property in our nation’s history.” – M. Pritt
“The use of pirated content to train generative AI models will harm sales for creators.” – M. Smith
The other speaker was more supportive of AI training regardless of the small matter of it being based on illegal copying, but did concede that “an AI model that routinely produces outputs that are infringing, such as regurgitations, might not be a fair use.” – E. Lee
He also argues that making stricter rules means that companies would go to other countries in search of less strict rules, but this isn’t a good argument: it would be like making less laws on drug dealing or whatever crime because other countries are less strict. Instead, this should be the reason why there needs to be a worldwide treaty to prevent ‘data mining’ of copyrighted materials in any country.
And he discussed the 40+ copyright law suits against AI companies in American courts, but this hearing in July 2025 is out of date: just under a year later, the figure has more than doubled!
Reference: ‘Examining the AI Industry’s Mass Ingestion of Copyrighted Works for AI Training,’ U.S. Senate Judiciary
As of June 2026, there are over 100 cases in the US legal system involving AI companies, and more across the world, as copyright holders keep finding out more about how tech companies secretly copied a massive amount of copyrighted material without their owner’s permission.
Reference: US and world maps with links to most cases, and other historic maps of the changes over time available at:
https://chatgptiseatingtheworld.com/category/map-of-ai-copyright-lawsuits/
Note: I am not connected in any way with the above site.
To be honest, as a fiction writer living in Australia with an arts degree, I don’t have any great knowledge of the legal systems of America or other countries where major tech companies are based. I’m author of books like ‘Mortal Wombat,’ which I spent more than 10 years writing, long before generative programs existed.
In writing this document, I feel a little like the guy in the Lego Movie giving the rousing speech to the group of superheroes, “I’m the least qualified person here.”
But what I do know is that tech companies have been taking a massive amount of copyrighted material and turning it into slop, and using that slop to compete against legitimate copyright holders without revealing who they’ve copied from. That’s not right, it’s not ethical, and I’m pretty sure it’s not legal.
And their claim of derivative copyright infringing slop being ‘transformative’ isn’t correct. Just like the actual Transformers, the Japanese cartoon, the pieces of the original robot can be seen in the new vehicle, like the Deceptacon/Autobots logos. In the same way that pieces of the original copyright holders work still appear in the new derivative work.
For instance generated images produced by the program ‘Stable Diffusion’ sometimes reproduced the original training image and a modified watermark for Getty Images. This is why the program developer Stability AI was sued by Getty Images – where it abandoned the main part of the case in a British court for the technicality of the program not being trained in the UK. But just because the program was produced in Germany shouldn’t mean that they can avoid copyright law – don’t the UK and Germany have all sorts of economic and copyright treaties? For instance, the Berne Convention and the TRIPS agreement – why couldn’t those have been applied somehow?
I don’t really want to get involved and start this protest. I’d much rather hide in my ‘hobbit hole’ and play World of Warcraft. But I also don’t want our future to drown in a sea of AI generated @#£%
Generative AI content can look fair, but feel foul, to paraphrase the hobbits description of the Mordor spy in Lord of the Rings. Sometimes it looks foul too! It often makes mistakes that no human would ever make, like generative pictures showing background crowd members without heads or limbs, or joined to someone else. Or messing up text in pictures. Generative content often feels lifeless or soulless.
When you watch real movies, listen to real music, read real books and so on, you know that they were the result of hours of labour by real people like yourself. Sometimes many humans worked on the artistic work in many fields such as editing etc. and had discussions and drafts before the final content was produced. This is missing from generative AI content, where a microchip spits out a patchwork of stolen material.
Ask yourself this question: over the course of your life, how much enjoyment have you received from movies, tv shows, music, games, books and other entertainment produced legitimately by copyright holders – I’m guessing hours and hours, right?, versus how much from derivative AI content – maybe a few short video clips or weird pictures? The problem is the derivative AI stuff is suffocating creators of the other, and the content’s worse, and it’s not legal anyway because it violates copyright.
Every moment the tech companies delay releasing information on what copyrighted data was copied only opens them up for more future law suits because of new material produced based on copyright infringing data.
Since about 2017, this Copyrighted material from numerous copyright holders has been secretly taken, then used by the tech companies to train generative programs, available from about 2023 onwards, to reassemble into ‘AI slop’ which competes against the legitimate copyright holders, threatening professionals right across the creative arts. Millions of artists, writers, musicians, actors, models, photographers, designers, animators, poets, podcasters, journalists and other professionals all over the world are losing out to tech companies’ computer servers, whose power and water usage are a drain on the environment.
*Reference: To just pick one action or protest from each field out of many:
*Artists, ‘The harm & hypocrisy of AI art’ by Matt Corrall, Corrall Design
https://www.corralldesign.com/writing/ai-harm-hypocrisy
*Writers, ‘More than 15,000 Authors Sign Authors Guild Letter Calling on AI Industry Leaders to Protect Writers’
*Musicians, ‘Is This What We Want?’ By 1000 musicians
https://www.isthiswhatwewant.com/
*Actors, ‘Hollywood’s stand against AI’
https://www.equaltimes.org/hollywood-s-stand-against-ai-a?lang=en
*Models, ‘British fashion models and the threats posed by indiscriminate use of Artificial Intelligence’
*Photographers, ‘Getty Images Is Suing the Company Behind Stable Diffusion, Saying the A.I. Generator Illegally Scraped Its Content’
*Games, ‘Our industry has been strip-mined’
https://www.theguardian.com/games/2025/dec/15/video-game-workers-protest-firings-the-game-awards
*Animation, ‘International Animation Unions Plan Protest Against AI’
https://variety.com/2025/film/global/animation-unions-anti-ai-protest-annecy-1236424470/
*Poets, ‘Page Against The Machine: On the Poetics of AI Refusal,’ Scottish Poetry Library
*Podcasts, ‘The podcast factory making 3,000 episodes a week,’
https://podnews.net/update/ai-slop
This example list is by no means complete. There are many more actions, protests and articles against generative AI and its potential copyright infringement.
*Then there is the massive impact AI is having on news media. The tech companies training method is described by publisher A.G. Sulzberger:
"A brazen theft of intellectual property that has occurred at an unprecedented scale. Tech giants strip-mine news websites without permission or compensation. They repackage these stolen goods as their own, siphoning off the audiences and revenue that otherwise would go to the news organizations that created this work. And this happens not just once during the training process, but countless times every single day."
He points out the society-wide impact too:
"A.I. companies have raided civilization’s entire corpus of original works, an act that also poses a danger to the future of books, movies, music, research and an array of other fields."
- Quoted from the speech, 'A.I., Journalism and the Uncertain Future of the Public Square', World News Media Congress, World Association of News Publishers, Marseille, June 2026
https://www.nytco.com/press/a-i-journalism-and-the-uncertain-future-of-the-public-square/
From many other campaigns and articles about AI's impact on news media, a few more examples :
*The 'News Not Slop' Campaign by the NewsGuild-CWA,
https://www.newsnotslop.org/demands
*'Artificial intelligence: journalism before algorithms,' National Union of (UK) Journalists,
https://www.nuj.org.uk/resource/artificial-intelligence.html
*'Real Journalists can lead the war against deepfakes,' Journalism Education & Research Association of Australia,
https://jeraa.org.au/role-of-journalists-vital-in-era-of-ai-generated-or-ai-edited-deepfakes/
Then there are many campaigns against the pollution, noise, power and water usage of AI data centres such as:
*‘AI and datacentres: a new climate threat’,
https://www.campaigncc.org/ai_data_centres_climate
*‘Get The Truth About Data Centers,’
*‘Stop Dirty Data Centers,’ NAACP,
https://naacp.org/campaigns/stop-dirty-data-centers
*‘Stop the AI Data Centre Frenzy,’ The Greens,
https://greens.org.au/vic/campaigns/stop-ai-data-centre-frenzy
*Or view the U.N. report, ‘Environmental Cost of Artificial Intelligence: Carbon, Water, and Land Footprints,’
Besides all this infringement and pollution, AI is not even working out smoothly for the industries where it's being adopted. There are of course complaints from people who AI is replacing, but there are also complaints from within the companies where AI is being used. If you search Youtube for 'AI backlash' you will find a variety of problems, from 'AI fatigue' to employers not getting back their return on AI investment, to retrenched employees being rehired after AI programs failed to work, or AI producing 'hallucinations' (mistakes which sound real), or employees being forced to use AI when there isn't a need for it, to customers being unhappy with AI products and service.
Reference: 'Nobody Actually Wants AI Anymore,'
https://www.youtube.com/watch?v=FQpZdCKgc6w
Other problems include the expensive nature of AI, for both the companies and its users, with the legal fees from ongoing copyright litigation, plus the costs of running large computer servers making hefty maintenance, power and water bills. There has been criticism that AI costs much more than the value of what it produces. Or an issue with different company employees encouraged to use ‘AI tokens’ until they became too expensive so they were banned from using them.
Reference: 'AI’s downfall is bitterly ironic,’
https://www.youtube.com/watch?v=7w_tjX04BDY
Then there's the problem which large AI companies have of being unable to stop their programs content being copied or ‘distilled’ by smaller AI companies, which seems to be standard practice in their industry. This ‘distillation’ sounds quite similar to the ‘diffusion’ of images used by AI program ‘Stable Diffusion’ in the Getty Images copyright case, so it’s a bit of poetic justice that they’re now finding themselves being distilled. When AI companies complained about this ‘distillation’ in February 2026, they received an unsympathetic community response with mocking comments like “They're plagarising our plagarism machine!”
Reference: 'AI Companies Who Steal Work Complain Competition Unfairly Stole Their Work, Get Laughed At,'
https://www.youtube.com/watch?v=EkpzQVgxKlg&t=174s
In addition to all the problems, the reassembled generated AI material enables the creation of dishonest deep fake imagery which causes scams, harassment and deception.
References, (I just picked one of each from a horrendous number of examples):
*‘How scammers use technology and AI’
*‘Artificial Intelligence and online harassment’
https://www.parkview.com/blog/artificial-intelligence-and-online-harassment
*‘AI Deception, Brief of the [United Nations] Secretary General's Scientific Advisory Board.’
https://unu.edu/cpr/policy-brief/ai-deception
This isn’t just wrong ethically and morally, it’s wrong legally.
It’s called COPYRIGHT INFRINGEMENT.
And companies can’t claim that’s a Trade Secret, as some do, because copyright infringement is illegal. Your Trade Secret can’t be illegal, that’s common sense.
If tech companies don’t release the data on what copyrighted information they’ve secretly copied under claim of Fair Use, and used to train generative AI programs to produce AI slop that competes against legitimate copyright holders, which makes the content ineligible for Fair Use - and also since illegal copyright infringement cannot be a Trade Secret, it won’t just mean many more law suits filed by copyright holders seeking damages. I believe that it proves the entire content of some companies could be considered illegal and may open the company up for compulsorary liquidation.
One American law professor which I sent this liquidation idea to, described it as “exceptionally unlikely to work,” due to copyright law being governed federally and state law covering dissolution of companies.
So it seems that an action can be pursued in state courts only after a ruling is made in U.S. federal court about the copyright infringement committed by these companies. There are actually a large number of current cases against AI companies working through federal or district courts. (The U.S. has 94 federal districts; small states have one district, large states have multiple districts.) The copyright cases as of June 2026 against AI companies in these federal/district courts are: California’s Northern District (55 cases), California’s Central District (7 cases), New York’s Southern District (37 cases), Illinois N.D. (4), Delaware (3), Massachusetts and Washington W.D. (2 each), Montana, Colorado, North Carolina W.D. (1 each)
Reference: https://chatgptiseatingtheworld.com/aicopyrightcasetracker/
So what state are AI companies corporated in? Most weren’t corporated in California where you might expect. It turns out many tech companies have corporated themselves in Delaware, the 2nd smallest state by area and 6th smallest by population, due to Delaware’s status as a ‘corporate haven,’ but that doesn’t mean they can avoid U.S. federal copyright law.
A Delaware district court is also where one of the early victories against AI occurred, in Thomson Reuters v. ROSS Intelligence (2025), where a judge ruled against the AI company for using summaries of judges opinions to train AI. Perhaps this hurt the legal system, now maybe judges would like to consider the way AI is hurting the rest of society?
It is worth noting that the Attorney General of Delaware can start the process to dissolve “any corporation” under 8 Delaware Code § 284, for the “abuse, misuse, or nonuse of its corporate powers.”
Reference: https://delcode.delaware.gov/title8/c001/sc10/index.html#284
I believe the violation of the entire world’s intellectual property rights and copyright law at once by AI companies is just such an abuse and misuse of corporate powers. If you agree with me, maybe you would like to contact the Attorney General of Delaware? I have already posted a letter to her, but she has not responded yet.
I wonder whether the Founding Fathers would approve of Delaware corporated companies which conduct no real business in Delaware breaking U.S. federal copyright law.
Such as whether the Copyright Clause may have been broken – if content being transformed into slop without permission is breaking this ‘exclusive right’? :
"To promote the Progress of Science and useful Arts, by securing for limited Times to Authors and Inventors the exclusive Right to their respective Writings and Discoveries." (U.S. Constitution, Article I, Section 8, Clause 8)
I don’t know the answer to that constitutional question and nothing here is meant as legal advice. I’m not a lawyer, and most of my understanding of copyright is based on being in a creative arts field; writing, art and images, where copyright is important. At least it was important before AI companies decided they were above copyright law and could copy anything they felt like, rewriting the rules to suit themselves. So not being a lawyer, all those complicated legal arguments are far beyond my understanding. If you are knowledgeable about American law, please consider working on the arguments to help defend the entire world’s artistic and creative products.
It may be an impossible mission to request big tech companies to reveal their ‘Trade Secret:’ all the copyrighted information which they’ve taken without permission. Of course they want us to take them at their word that they kept to Fair Use regulations, while they secretly plundered the entire world’s copyrighted information, then claim that they can’t reveal the information because it’s their ‘Trade Secret.’ Do you trust them?
I admit that this mission may have an astronomically low chance of success, but that never stopped anyone in Star Wars, right; “Never tell me the odds!”
While researching this document, I was astounded by the vast number of campaigns, protests and criticisms of AI by so many people in so many fields from so many angles, which I've only hinted at here. They really feel like the array of rebels in Star Wars banding together to fight a technologically sophisticated yet evil empire of copyright infringing AI companies which care more about their bottom line, than the environment, the arts or humanity. The spherical shape of the Death Star is not unlike the shape of the 'AI bubble.'
But we have Yoda on our side. Literally; he's one of the many copyrighted characters owned by Disney for which they are suing AI company Midjourney for copying without permission.
An empire is also what the AI industry is called in the book ‘Empire of AI’ by journalist Karen Hao, who interviewed 300+ people in the AI industry to form this theory:
“Over the years, I’ve found only one metaphor that encapsulates the nature of what these AI power players are: empires... [they] seize and extract precious resources to feed their vision of artificial intelligence: the work of artists and writers; the data of countless individuals posting about their experiences and observations online; the land, energy, and water required to house and run massive data centers and supercomputers. So too do the new empires exploit the labor of people globally to clean, tabulate, and prepare that data for spinning into lucrative AI technologies. They project tantalizing ideas of modernity and posture aggressively about the need to defeat other empires to provide cover for, and to fuel, invasions of privacy, theft, and the cataclysmic automation of large swaths of meaningful economic opportunities.”
Reference: ‘Empire of AI: Inside the reckless race for total domination.’
https://www.amazon.com.au/dp/B0F38RZP32
In one interview she explains how the promoters and supporters of the 'AI empires' act like they’re part of a religious cult!
Reference: ‘A.I. is a Religious Cult with Karen Hao,’ Interview by Adam Conover
https://www.youtube.com/watch?v=6ovuMoW2EGk
The above interview is enlightening, pointing out this absurd cult following which AI has received, playing off fear of ‘the other side’ introducing a similar AI system to the one they're promoting. I imagine a fantasy setting with an AI cultist saying something like: “The other side’s AI threatens us all, brother, but our side’s AI is not evil like theirs. So give us your Copyrighted materials, brother, and I will recite the incantation of Illegal Infringement and utter a prayer of out-of-context Transformation, then the secret spell of Unfair Use will make your Copyright disappear and the Derivative Slop will be summoned!” (Then appears one of those headless twisted monstrosities found in AI generated crowd pictures.)
The absurdity of it all would be hilarious, if it wasn’t tragic for creators, society and the environment.
These ‘AI cultists’ point to China to scare Westerners. However, rather than an ‘AI arms race’ with China, how about ‘Disarming AI’ as Pope Leo XIV has suggested? For instance we could have a U.S.-China treaty similar to the START treaty that slowed the Cold War arms race. Both sides could agree to close down a proportion of their polluting data centres, or each unincorporate a certain number of copyright-infringing AI firms? Try that suggestion next time an AI promoter wants to scare you with fearmongering.
China has their own issues with generative AI versus copyright law, with five court cases before April 2025.
Reference: Authors Alliance, ‘China’s Controversial Court Rulings on AI Output.’
China, like the United States, is signatory to the Berne Convention for the Protection of Literary and Artistic Works and the TRIPS agreement, Trade-Related Aspects of Intellectual Property Rights. On the other hand, generative AI offers no such protection, and are lobbying for more ‘licence to steal’ data mining exemptions all around the world. It doesn’t matter where the AI company is based, they’re the ones taking away copyright rights of the whole world’s creators.
The tactic of AI companies scaring people by pointing out future harms their products might cause as a way of hyping them up, is called ‘Doom trolling’ by Georgetown University Computer Science Professor Cal Newport, who points out this weird strategy is unique in the business world.
Reference: ‘Dear AI Companies: Stop the “Doom Trolling”’
https://calnewport.com/dear-ai-companies-stop-the-doom-trolling/
There has been other criticism from within their field, for instance current AI large language models said to not be an artificial intelligence at all, and instead a ‘technological hack,’ and a form of ‘pattern recognition’, as they were described in 2025 by the Professor of the Foundations of Artificial Intelligence in the Department of Computer Science at the University of Oxford.
Reference: ‘Oxford's AI Chair: LLMs are a HACK.’
https://www.youtube.com/watch?v=7-UzV9AZKeU
In addition, the huge number of computer data centres being built don't just pollute the environment, they have also reduced the supply of computers and their parts for everyday people, and driven up their price during 2025-26 up to one thousand percent more!
Reference: ‘I Was Right About AI.’ [in referring to previous video, ‘How AI Will Fail Like The Music Industry.’]
https://www.youtube.com/watch?v=aXy8mQeuObk
Whether you believe in using AI or not, the main point is this: tech companies can’t keep secret what information they’ve taken from an unknown number of copyright holders and claim that’s Fair Use. Fair Use guidelines specify a minimum amount of content taken, not all – and how is anyone supposed to know how much has been taken if the companies are keeping secret what and how much they’ve copied? How could you know if something produced with generative AI does or doesn’t breach copyright? And there are many clear cases where it has, such as direct portions of copyrighted images taken and reassembled into a new derivative copyright violating image.
For example, in 2025 when Disney teamed up with Universal Pictures, joined later by former rival Warner Brothers, to sue Midjourney, this AI company was described as “a bottomless pit of plagiarism.”
Reference: ‘Disney Enterprises Inc. v. Midjourney Inc.’, District Court, C.D. California
https://www.courtlistener.com/docket/70513159/disney-enterprises-inc-v-midjourney-inc/
In the above page, Yoda is mentioned in points 38, 82, 87, 143, 150 and 178 of their complaint, while Exhibits C & D also show many clear violations with generated images using copyrighted characters.
So people using these generative programs can’t be sure that the resulting material doesn’t violate copyright in some way, and with laws changing in different countries, they might be liable for copyright infringement sometime in the future.
Also consider that any content produced with generative AI is ineligible for copyright, and therefore public domain in most jurisdictions. So anyone can quite legally copy generative AI material and almost do what they like with it. Which means that the result of generative AI is to take copyright holders material and illegally transform it into public domain material – there’s no way it’s fair use to delete copyright holders’ copyright! Generative AI is basically a machine that copies, patches together and deletes the copyright of the original copyright holders, turning the resulting transformation into public domain in seconds, rather than waiting the 70 years after the author’s death for which entering the public domain is supposed to happen under U.S. Copyright Law.
Reference: this Wikimedia commons page covering world copyright rules:
https://commons.wikimedia.org/wiki/Commons:Copyright_rules_by_territory
In the above page, look at the collaborative effort and detail which editors have put together to cover copyright rules, with a subpage for every country in the world - rules which generative AI wants to ignore.
Indeed, American AI companies give Americans less copyright protection than Chad, Madagascar, Luxembourg, Kazakhstan or North Korea, which like 182/195 countries are signatory to the Berne Convention for the Protection of Literary and Artistic Works, giving minimums of 25 years copyright protection for photographs, and 50 years after the author’s death for most other works. And 164 countries are also signatories to the TRIPS agreement, (Trade-Related Aspects of Intellectual Property Rights) which also gives 50 year minimum copyright terms. Reference: Wikipedia.
The world needs a new treaty to protect creators from data mining by tech companies, to stop any ‘data mining exception.’ This is an ‘exception’ from the law, that allows companies to violate copyright law – oh, sorry, it’s not illegal because they've been given an ‘exception’ from the law. In any case, data mining of copyrighted materials should be illegal, and there should be a worldwide treaty banning it, an update to the Berne Convention.
This would prevent tech companies from using their pathetic argument that, ‘if you stop us stealing copyrighted materials here, people will just go to X country where they can steal copyrighted materials instead.’
I’m glad a similar argument isn’t used in every world law, where society bases its laws not on what’s right, fair or just - but on how the law is treated in whichever place happens to have the weakest laws in the world.
Even if this data mining ‘licence to steal’ is kept in place, companies should at least be forced to disclose what they have stolen – sorry, copied copyrighted information without their owner’s permission but given an exception from the law to do so, from whom. Creators have the right to know if their work has been copied.
And if every country banned data mining copyrighted theft under a new worldwide treaty, then no-one would be able to steal copyrighted materials.
When an AI generated image is produced, it is ineligible for copyright in both the European Union, the United States and many other jurisdictions, and immediately enters the public domain on its creation. Now everyone is free in theory to copy that work and make it into any work they like. The problem isn’t just that the image is being used in a way unintended by the original creator, but it also opens up its potential for being used in ways unintended either by the original creator, or the maker of the AI generated image, because it’s now not protected under copyright law. The AI content isn’t even respected by other AI companies, which often ‘distill’ their rivals content to make their own programs.
Before you think of ways you could use AI programs to make art or fiction, remember that the content produced is similar to fan-art or fan fiction, with the potential for trouble with, or even being sued by the original creator/s. But this is a much worse situation than fan art, because with generative AI the creator/s may be unknown – you don’t know for sure that some piece of the work isn’t a direct copy of some work you’ve never seen or heard. Plus you have little to no copyright protection for others to misuse the generated work in other ways, such as reselling it under a different name, which in turn might make you liable for someone in the future doing something else with the un-copyrighted generated work which you can’t predict.
With so many copyright holders infringed by generative programs turning their copyrighted material into public domain ‘AI slop’, there’s just going to be more and more litigation, as cases involving AI companies rose to over 100 in courts worldwide in 2026.
The below chart shows the copyright cases just in America. The trend was already going up, but Anthropic’s $1.5 billion settlement announcement in September 2025 showed creators can win, which might have helped cause cases against AI companies to skyrocket:
Source (on the original image, each dot is a clickable link to the actual case):
https://chatgptiseatingtheworld.com/ai-copyrightcase-timeline/
The AI bubble might soon burst, or ‘drown,’ if you will, in a sea of copyright law suits, and perhaps rightfully so, for a business model built around copyright infringement. If you've invested in AI companies, maybe sell your shares before the AI bubble bursts? Why not try 'ethical investing' instead?
Besides, AI companies may not last long beyond 2100 anyway. Because you can’t maintain computer data centres without oil, which is a critical component used in microchip production. And the Earth is going to run out of oil this century, that’s inevitable. We should be thinking about how to best use the planet’s last remaining oil reserves to prepare for a future without it, and I’m not sure generative AI making public domain copyright violations will be much help.
Better to get rid of generative AI ahead of time, before it poisons every creative arts field with derivative copyright infringing slop, enables the production of dishonest deep fake imagery that is causing so much harm to society, and pollutes the environment on its way out, all based on the mass theft of copyrighted material without permission.
Given all the problems generative AI is causing for society it shouldn't be allowed to operate where it hasn’t even obtained its training data legally. Companies should release copyright holders data, pay compensation to creators where needed, then only operate under a transparent, legal model.
When companies release this data on what copyrighted information their programs have been trained, it means creators whose works have been unlawfully copied can be justly compensated by the companies which used them without permission. Then the system can move forward with full transparency and less need for litigation. Then creators will have the right to opt out of having their creations copied if they wish, without the danger of having their own work being illegally copied and used against them to profit someone else.
Conclusion: It is an outrageous situation that programs which produce content based on mass copyright infringement are harming the world in such a variety of ways. The AI companies money, power and influence has been illegally gained based on thieving the copyrighted materials of the entire world. The imperial style power they are wielding and the money they have made is not their own: it was collectively stolen from the entire artistic product of the world. This was not Fair Use, it is not Fair Use to have their programs compete with and replace original creators. It is not Fair Use that tech companies' programs have allowed the creation of deep fake imagery that causes scams, harassment and deception. It is not Fair Use that AI companies servers are causing environmental pollution, draining power and water resources. It is not Fair Use that AI programs are replacing human jobs when their expensive programs don’t even work properly; they make hallucinations, give employees stress or fatigue and produce inferior products. It is not Fair Use that the copyrighted artistic products of the world are combined by generative programs into derivative public domain ‘AI slop’ which has no copyright protection, and can be reused by anyone for any purpose, deleting the copyright of the original creators.
Many of the world’s countries united in signing the Berne Convention for the Protection of Literary and Artistic Works. Now the world needs a new treaty to protect creators, which stop any tech company anywhere in the world from secretly thieving copyrighted data from any creative field. If 182/195 countries can sign the Berne Convention, they should be able to come together for a new treaty to force tech companies to be completely transparent with their data training. Only by forcing tech companies to release all copyrighted data, and putting in place a worldwide treaty to stop them from ever illegally thieving the creative products of the world again, can the rights of the world’s creators be protected, for so many people who just want to make an honest living in the creative arts.
Note: I am also submitting this protest to the Australian Senate’s Environment and Communications References Committee regarding ‘Artificial intelligence and data centres.’
Although I don’t know if the protest will achieve anything. There are other bigger protests out there such as the Pause AI movement at
the Statement on AI training:
https://www.aitrainingstatement.org/
or the Stealing isn’t Innovation campaign:
https://www.stealingisntinnovation.com/
And there are other current and former calls for AI companies to release copyrighted data, including:
*The ‘Authors Guild Open Letter to AI Leaders’ in November 2023
https://actionnetwork.org/petitions/authors-guild-open-letter-to-generative-ai-leaders
*The ‘Generative AI Copyright Disclosure Act’, introduced in U.S. Congress in 2024
https://en.wikipedia.org/wiki/Generative_AI_Copyright_Disclosure_Act
*The ‘Stop AI Theft’ campaign in Australia 2025
https://meaa.good.do/stopaitheft/stop-metas-AI-theft/
*The ‘Copyright Labeling and Ethical AI Reporting Act’, introduced in the U.S. Senate in February 2026, now being discussed:
https://copyrightalliance.org/press-releases/introduction-clear-act/
*California’s ‘Generative AI Training Data Transparency Act’ (2026)
https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202320240AB2013
***
While Pope Leo XIV has called for AI to be ‘disarmed’ in the 2026 encyclical letter, ‘ON SAFEGUARDING THE HUMAN PERSON IN THE TIME OF ARTIFICIAL INTELLIGENCE’,
https://www.vatican.va/content/leo-xiv/en/encyclicals/documents/20260515-magnifica-humanitas.html
*Even here at change.org are dozens of examples:
Protect authors’ livelihoods,
Ban AI in elections,
https://www.change.org/p/protect-our-democracy-ban-ai-in-elections
Stop AI image theft,
https://www.change.org/p/stop-ai-image-theft-introduce-urgent-protections
Make it illegal to create AI-generated nudes,
https://www.change.org/p/make-it-illegal-to-create-ai-generated-nudes
Stop Generated AI From Invading The Animation Industry,
https://www.change.org/p/stop-generated-ai-from-invading-the-animation-industry
Protect musicians from fraud,
https://www.change.org/p/protect-musicians-from-fraud
Protect our art and data from AI companies,
https://www.change.org/p/sign-the-manifesto-protect-our-art-and-data-from-ai-companies
And on and on. Last I checked change.org recorded more than 1000 results for “generative AI” – those are separate protests!
So my protest may be lost in the crowd, but it’s a small thing I can do which seems worth starting to help protect EVERY COPYRIGHT HOLDER IN THE WORLD FROM HAVING THEIR BEAUTIFUL COPYRIGHTED MATERIAL MISUSED AND TRANSFORMED INTO PUBLIC DOMAIN ‘AI SLOP’ WITHOUT THEIR PERMISSION.
That’s why this is a demand for
ALL TECH COMPANIES TO RELEASE ALL DATA ON ALL COPYRIGHTED INFORMATION TAKEN FROM ANY COPYRIGHT HOLDER IN SECRET WITHOUT THEIR PERMISSION, AND USED TO TRAIN GENERATIVE AI PROGRAMS.
(In other words, Obey Copyright Law! Or have governments Enforce Copyright Law.)
Either companies release this information voluntarily, or it will be released through legal action by the courts which is already happening in many cases worldwide. This copyrighted information must be protected, for it represents the livelihoods for so many people right across the creative arts.
Because You, the People, deserve not to have your artistic creations stolen.
☆HAPPY 250TH BIRTHDAY AMERICA!!!!!☆

Petition Updates
Share this petition
Petition created on 18 June 2026